Unleashing GPU Power: Parallel Computing with CUDA
Introduction
With the recent advancements in AI, the demand for more and more calculations has increased. GPUs have been used for many AI projects as their computation ability can be better than CPU’s for certain tasks.
What is parallel computing?
Parallel computing is a type of computation where you can perform calculations independently, and therefor in parallel. This allows you to solve complex problems faster than a sequential approch.

Here is a little example to illustrate. Basicly for the same amount of instructions to execute , the parallel approach is faster than the sequential one.
Using GPUs rather than CPUs ?
GPUs are better suited for parallel computing than CPUs because they are designed to handle many calculations simultaneously. A typical CPU has a few cores, while a GPU has thousands of cores. This allows a GPU to perform many calculations in parallel, making it much faster than a CPU for certain types of computations.
When it comes to parallel computing, GPUs are much better than CPUs. They are designed to handle many calculations simultaneously, making them much faster than CPUs for certain types of computations. This makes them ideal for scientific computing, simulations, and other fields where large amounts of data need to be processed.
Getting started with CUDA
I used a Visual Studio environment to write and run the CUDA code. The first step is to install the CUDA toolkit, which includes the CUDA compiler and other tools needed to develop CUDA applications. Once the toolkit is installed, you can start writing CUDA code and running it on your GPU.
My code is simple matrix multiplication program than compares the running time for a CPU and GPU matrix multiplication. I also test the performance for different matrix sizes.
The code
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// GPU Matrix multiplication
__global__ void matrixMulKernelGPU(int* c, const int* a, const int* b, int n) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < n) {
int sum = 0;
for (int k = 0; k < n; k++) {
sum += a[row * n + k] * b[k * n + col];
}
c[row * n + col] = sum;
}
}
// CPU Matrix multiplication
void matrixMulCPU(int* c, const int* a, const int* b, int n) {
for (int row = 0; row < n; row++) {
for (int col = 0; col < n; col++) {
int sum = 0;
for (int k = 0; k < n; k++) {
sum += a[row * n + k] * b[k * n + col];
}
c[row * n + col] = sum;
}
}
}
// Function to init the array with random numbers
void randomInts(int* a, int size) {
for (int i = 0; i < size; i++) {
a[i] = rand() % 100; // Random numbers between 0 and 99
}
}
// Host is the CPU, Device is the GPU
// size is the size of the matrix (size x size)
void MatMultBench(int size) {
int* a, * b, * c; // Host copies of a, b, c
int* d_a, * d_b, * d_c; // Device copies of a, b, c
int byte_size = size * size * sizeof(int);
clock_t startCPU, endCPU;
cudaEvent_t start, stop;
float GPU_time, CPU_time;
// Initialize CUDA events
cudaEventCreate(&start);
cudaEventCreate(&stop);
// Print
printf("Matrix size: %d x %d\n", size, size);
// Allocate space for device copies of a, b, c
cudaMalloc((void**)&d_a, byte_size);
cudaMalloc((void**)&d_b, byte_size);
cudaMalloc((void**)&d_c, byte_size);
// Allocate space for host copies of a, b, c and setup input values
a = (int*)malloc(byte_size); randomInts(a, size * size);
b = (int*)malloc(byte_size); randomInts(b, size * size);
c = (int*)malloc(byte_size);
// Start GPU timing
cudaEventRecord(start);
// Copy inputs to device
cudaMemcpy(d_a, a, byte_size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, byte_size, cudaMemcpyHostToDevice);
// Setup the execution configuration
dim3 threadsPerBlock(16, 16); // 16x16 is a common choice, modify as needed
dim3 blocksPerGrid((size + threadsPerBlock.x - 1) / threadsPerBlock.x, (size + threadsPerBlock.y - 1) / threadsPerBlock.y);
// Launch the kernel on the GPU
matrixMulKernelGPU << <blocksPerGrid, threadsPerBlock >> > (d_c, d_a, d_b, size);
// Copy result back to host
cudaMemcpy(c, d_c, byte_size, cudaMemcpyDeviceToHost);
// Stop GPU timing
cudaEventRecord(stop);
// Wait for GPU to finish
cudaEventSynchronize(stop);
// Calculate GPU time
cudaEventElapsedTime(&GPU_time, start, stop);
printf("Time taken for GPU: %f ms\n", GPU_time);
// CPU Matrix multiplication, monitor time with libc
startCPU = clock();
matrixMulCPU(c, a, b, size);
endCPU = clock();
CPU_time = (float)(endCPU - startCPU) * 1000 / CLOCKS_PER_SEC;
printf("Time taken for CPU: %f ms\n\n", CPU_time);
// Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
free(a); free(b); free(c);
cudaEventDestroy(start);
cudaEventDestroy(stop);
}
int main() {
// 1, 2, 4, 8, 16, ... until 4096
for (int i = 1; i <= 4096; i *= 2) {
MatMultBench(i);
}
return 0;
}
The performance difference
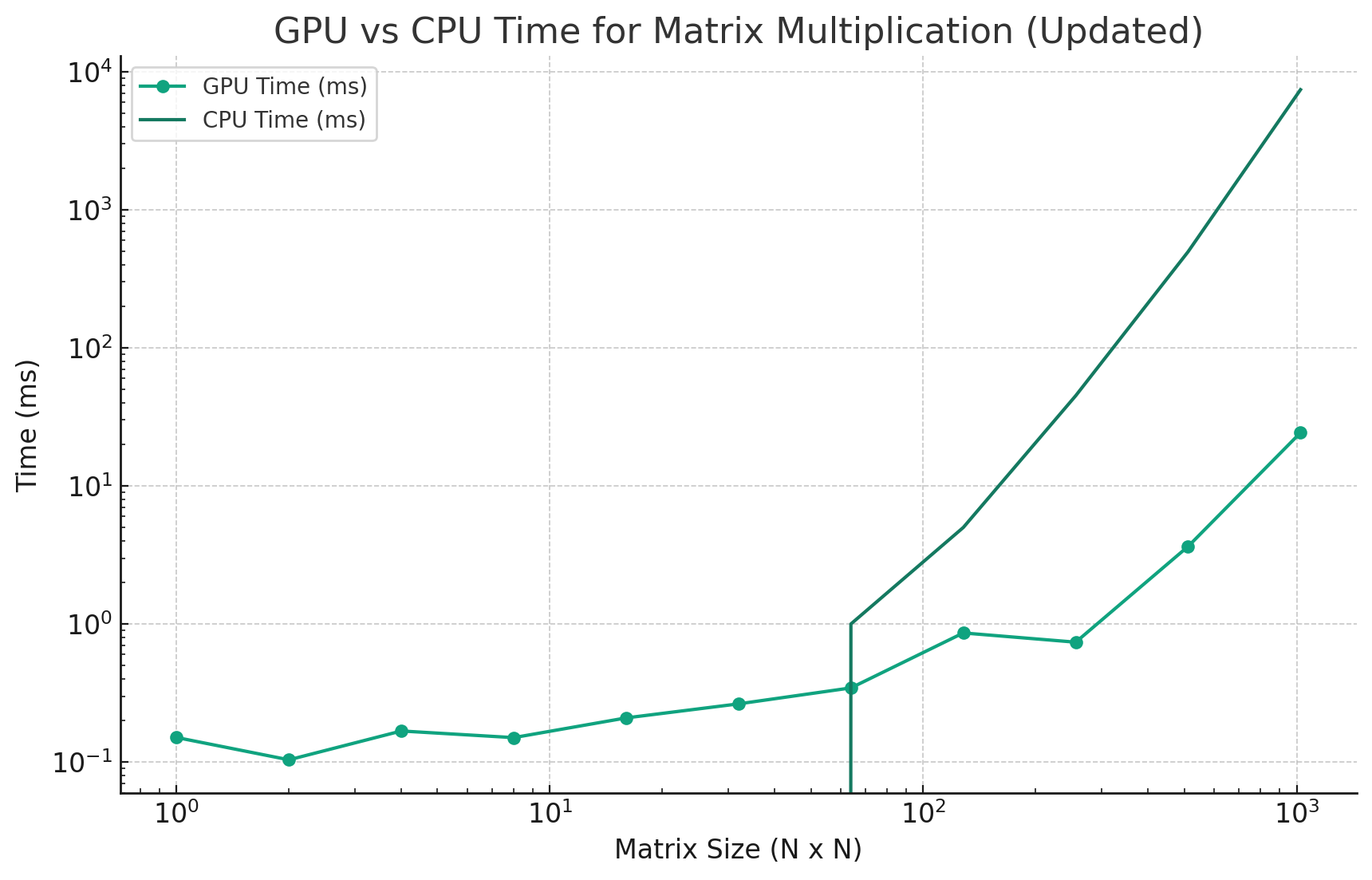
As you can see after a certain matrix size, the GPU outperforms the CPU by a significant margin. This is because the GPU is able to perform many calculations in parallel, while the CPU can only perform a few calculations at a time.
The CPU is better for relatively small matrix sizes because copying memory to and from the GPU takes time, so for small matrix sizes, the downside of copying memory to and from the GPU outweighs the benefits of parallel computing. However, as the matrix size increases, the benefits of parallel computing start to outweigh the overhead of copying memory to and from the GPU.
Conclusion
In this article, we explored how to leverage the power of GPUs for parallel computing using CUDA. We saw that the GPU is much faster than the CPU for certain types of computations, such as matrix multiplication. This is because the GPU is able to perform many calculations in parallel, while the CPU can only perform a few calculations at a time.
Matrix multiplication is a common operation in AI, and it is used in many machine learning algorithms. By leveraging the power of GPUs for matrix multiplication, we can speed up the training of machine learning models and make AI more efficient. This can explain the big interest in using GPUs for parallel computing in the AI field.
If you wan’t to check the code, you can find it Github repo